https://arxiv.org/pdf/1907.07225
DeepTrax: embedding graphs of financial transactions 논문을 훑어고
금융 거래 데이터를 활용하여, 거래 항목을 임베딩 후, 임베딩 결과를 시각화 해 보았습니다.
DeepTrax: embedding graphs of financial transactions
1. INTRODUCTION
금융 거래 이종 그래프(heterogeneous graph)로 표현하고, 이들간의 거래를 edge로 표현하는것은 유용한 접근법이 될 수 있지만, 이러한 그래프는 매우 높은 차원을 가지고, 희소하게 연결되어 있어 일반적인 머신러닝 작업에 활용하기 어렵습니다.
최근 몇년 동안(논문 출판 년도 : 2019년) 이러한 그래프의 latent representation을 학습하는 방법으로 임베딩 기술이 인기를 얻고 있으며, 이 임베딩 기술을 활용하여 유사돌르 측정하거나, 지도학습 모델의 피쳐로 사용할 수 있습니다.
(그래프 합성 네트워크(Graph Convolutional Networks, GCN), DeepWalk, node2vec)
이 논문에서는 그래프 임베딩 기법을 적용한 사례를 제시합니다.
2. RELATED WORK
(생략)
3. METHODOLOGY
신용카드 거래 그래프는, 구매자와 판매자의 이분 그래프로 표현할 수 있으며, 거래를 edge로 표현 할 수 있습니다.
이 이분 그래프에서 경로를 구할 수 있습니다. (ex. 사용자1 -> 상점 A -> 사용자 2) 우리는 이 경로를 임베딩 학습에 활용할 예정입니다.
그래프를 구하는 방법 중 하나로, 상점간의 edge는 동일한 사용자가 특정한 시간 구간 (time window)에서 거래 한 적이 있음을 나타낼 수 있습니다. 또 이 거래의 시간차를 edge의 weight로 사용할 수 있습니다.
edge가없는 노드쌍을 무작위로 샘플링하여, 네거티브 샘플링을 사용할 수 있습니다.

m ∈ V 은 상점을 나타내며, 매핑 함수 φ : m ∈ V → R^d 는 임베딩 표현을 의미합니다.
k는 음성 샘플의 수이며, m_pos는 학습 데이터, m_neg는 네거티브 샘플링 데이터를 의미합니다.
이 목적함수를 최적화 하는 것은 그래프 상에서 서로 다른 상점간의 열결된 관계를 나타내는 임베딩을 학하는것과 같습니다.
4. RESULTS
(생략, 임베딩 성능을 평가하기 위해서 활용 용도에 따라 정량, 정성적 분석을 진행했습니다.)
5. CONCLUSION
금융 거래의 순서를 그래프로 표현하고, 고객이 주어진 time window 안에 두 상점에서 거래를 한 경우, 두 상점간 edge를 형성됩니다. 이후 기존에 인기있는 그래프 임베딩 기법을 적용하여 저차원 임베딩 모델을 생성합니다. (ex. skip-gram)
실험 결과, 이 접근 방식이 의미 있는 임베딩을 생성할 수 있음을 확인하였습니다.
코드로 구현해보기!
1. 데이터
캐글에 웹 쇼핑몰 데이터가 있어서 사용하였습니다.
(https://www.kaggle.com/datasets/mkechinov/ecommerce-behavior-data-from-multi-category-store)
## 데이터 로드
import kagglehub
# Download latest version
path = kagglehub.dataset_download(
"mkechinov/ecommerce-behavior-data-from-multi-category-store",
)
print("Path to dataset files:", path)
사용자 세션에 따라 view, click, purchase 로 구분된 event_type을 포함한 구매 정보가 있습니다.

2. 학습데이터 생성
## 데이터 전처리
# 임베딩 대상을 카테고리 코드 + 브랜드 정보를 사용하도록 합니다.
df['target'] = df['category_code'] + '.' + df['brand']
# 데이터는 구매 데이터만 사용하며, 브랜드, 카테고리 정보가 없는 경우 사용 X
filtered_df = df[
(df['event_type'] == 'purchase')
& ( ~ df['target'].isna())
]
# 거래 건수가 너무 작은 데이터 필터링, 8인 이유 : 그림이 이쁘게 나오기 때문
target_value_counts = filtered_df['target'].value_counts()
target_list = target_value_counts[target_value_counts > 8].index.values
target_set = set(target_list)
## 학습데이터 생성
from datetime import datetime, timedelta
TIME_FORMAT = '%Y-%m-%d %H:%M:%S %Z'
MAX_TIME = '2999-01-01 01:03:00 UTC'
TIME_WINDOW = 60*60
result = []
for session_id, group in tqdm(filtered_df.groupby("user_session")):
group = group.sort_values("event_time")
# 유효한 쌍을 생성
for (i, row1), (j, row2) in combinations(group.iterrows(), 2):
if row1['target'] not in target_set or row2['target'] not in target_set:
continue
time_diff = abs(
datetime.strptime(row1['event_time'], TIME_FORMAT)
- datetime.strptime(row2['event_time'], TIME_FORMAT)
)
if time_diff <= timedelta(seconds=TIME_WINDOW) and (row1["target"] != row2["target"]):
result.append((session_id, row1["target"], row2["target"], TIME_WINDOW - time_diff.seconds))
result_df = pd.DataFrame(result, columns=["session_id", "name1", "name2", "weight"])
# 마지막으로 weight를 0~1사이로 변경
from sklearn.preprocessing import MinMaxScaler
transaction_df = result_df.groupby(['name1', 'name2'], as_index=False)['weight'].mean()
scaler = MinMaxScaler()
transaction_df['weight'] = scaler.fit_transform(transaction_df[['weight']])

3. 모델 구현 및 학습
# 모델 정의 및 학습
import networkx as nx
import numpy as np
from gensim.models import Word2Vec
class DeepTrax:
def __init__(self, transactions):
self.transactions = transactions
self.graph = self.create_graph()
self.embeddings = None
def create_graph(self):
G = nx.Graph()
for source, target, weight in self.transactions:
G.add_edge(source, target, weight=weight)
return G
def random_walk(self, start_node, walk_length):
walk = [start_node]
for _ in range(walk_length - 1):
current_node = walk[-1]
neighbors = list(self.graph.neighbors(current_node))
if neighbors:
walk.append(np.random.choice(neighbors))
else:
break
return walk
def perform_walks(self, num_walks, walk_length):
walks = []
for node in self.graph.nodes():
for _ in range(num_walks):
walks.append(self.random_walk(node, walk_length))
return walks
def train_embeddings(self, walks):
model = Word2Vec(walks, vector_size=8, window=5, min_count=1, sg=1)
self.embeddings = model.wv
def embed_graph(self, num_walks=10, walk_length=10):
# 랜덤 워크를 통한 path(문장)을 생성하고
walks = self.perform_walks(num_walks, walk_length)
# 그 결과를 Word2Vec 모델을 사용하여 임베딩
self.train_embeddings(walks)
deeptrax = DeepTrax(transaction_df[["name1", "name2", "weight"]].values)
deeptrax.embed_graph()
## PCA알고리즘을 사용하여 2차원으로 변환
from sklearn.decomposition import PCA
entities = deeptrax.embeddings.index_to_key
X = np.array([deeptrax.embeddings[entity] for entity in entities])
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
embeddings_df = pd.DataFrame(data=X_pca, columns=['PCA1', 'PCA2'])
embeddings_df['Entity'] = entities
# Categort정보를 색상으로 표현하기 위해 추가
embeddings_df['Category'] = embeddings_df['Entity'].apply(lambda x: x.split(".")[0])
4. 임베딩 시각화
## plotly는 짱입니다.
import plotly.express as px
import plotly.offline as pyo
## Plotly를 사용하여 시각화 (text 제거)
fig = px.scatter(
embeddings_df,
x='PCA1',
y='PCA2',
# text='Entity',
color="Category",
)
fig.update_traces(textposition='top center')
fig.update_layout(
title='PCA of DeepTrax Embeddings',
xaxis_title='PCA Component 1',
yaxis_title='PCA Component 2'
)
fig.show()

다음 사진을 보면 text를 제거 한 이유를 알 수 있습니다.
# Plotly를 사용하여 시각화 2
fig = px.scatter(
embeddings_df,
x='PCA1',
y='PCA2',
text='Entity',
color="Category",
)
fig.update_traces(textposition='top center')
fig.update_layout(
title='PCA of DeepTrax Embeddings',
xaxis_title='PCA Component 1',
yaxis_title='PCA Component 2'
)
fig.show()

// TODO: tistory에서 동적으로 plotly를 동적으로 사용할 수 있도록 수정
일부 구간을 확대하여, 유사한 아이템이 모여있는지 확인





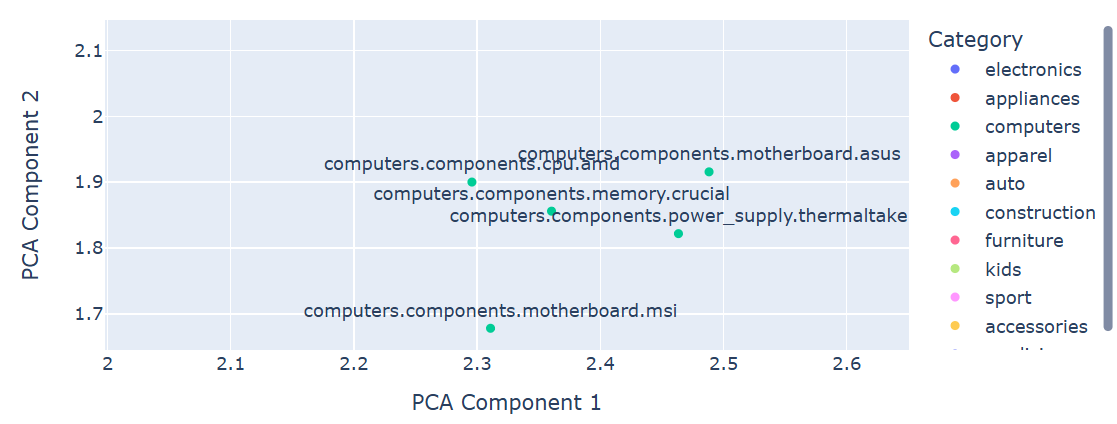

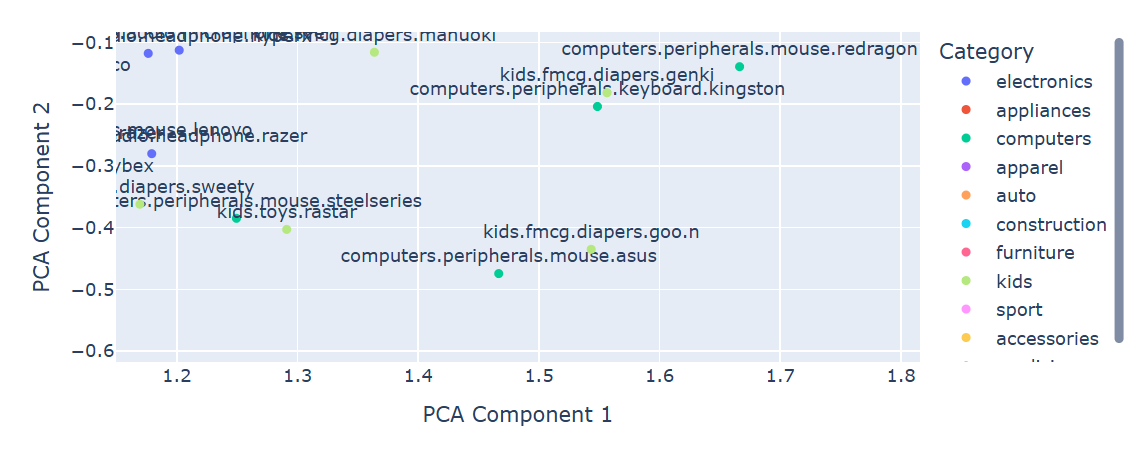
귀저기(diapers)가 왜 키보드 마우스랑 같이 있을까요?
어쩌면 이유가 있을 수 있습니다. 🤔

결론
DeepTrax: embedding graphs of financial transactions 논문을 (필요한 부분만)읽고 결과를 코드로 구현 & 시각화를 해 보았습니다.
각 거래되는 항목 (상점, 카테고리) 의 자체 정보를 하나도 사용하지 않고, 사용자의 거래 정보만을 사용해서 임베딩을 진행 해 보았습니다.
시각화 결과에서, (일부를 제외하고) 가까운 노드들이 유사한 카테고리에 있는것을 정성적으로 확인 할 수 있었습니다.
'Machine Learning > 기타' 카테고리의 다른 글
| 2024년에 한 생각과 2025년에 할 생각, 머신러닝 엔지니어는 어디로 가야 하는가? (0) | 2024.12.31 |
|---|---|
| 시계열 분류 모델을 위한 딥러닝 아키텍쳐 (0) | 2022.11.06 |
| Auto ML : FLAML 패키지 설명 & 사용기 (1) | 2022.10.03 |
